向多台机器分发文件 - bounce
最近在公司遇到了把一个几十G的虚拟机镜像文件分发到10来台机器上的问题,前期基础设施没有搭建好到后来就是会比较痛,如果这些机器用puppet或者chef管理起来了的话这事儿或许会好办一些。
首先当然不能手动一台一台拷贝。
其次也不能同时向这十几台机器,因为:
- 假定文件size是S,出口带宽是B,机器数目是C,
- 那么分发时间是S/(B/C),等于(S/B)*C,还是相当于一台一台拷贝的速度
有没有更快的方案?
很自然的我们想到了非常高大上P2P方案,这个业界传说facebook和Twitter都在用,用一个定制版的BitTorrent向他们的上千台线上服务器做部署。其实最早听说facebook在用了,但是没有开源出来,Twitter虽然听说的晚,但是却开源了他们的项目,叫Murder,赞Twitter。
因为BT协议的基本原理是把文件打散成块,多台peer机器之间频繁交换文件块。一个文件块从拥有文件的母体机器传输到另外几台机器之后,没有这个文件块的机器就可以从这几台机器去取文件而不仅仅只是从母体去取,复用程度大大提高,粗粗感觉一下似乎确实会快很多。
Murder是用Python写的,因为用到了Python的BitTorrent库BitTornado。然后在外面用Capistrano做了包装,可以敲cap做部署,也可以直接调用作者写的python脚本(https://github.com/lg/murder/tree/master/dist),参见这篇博客。
这种方案我试了一下,还是慢,无论是用Murder还是用MlDonkey做种用原生的BitTorrent,原因是用BT在我的环境下传输速率本身就慢,占不满带宽,我也懒得深究为什么了,决定采用B计划。
B计划跟BT协议类似,但是不再把文件打散成块了:先把文件从最开始的机器A拷贝给机器B,然后机器A和机器B同时向机器C和机器D拷贝,如此下去。。。因为同时拷贝的机器是呈指数级别上升的,所以越到后来分发速度还是挺客观的呵呵,但是起步时分发速度还是太慢。
怎么证明这种方式最起码会比从一台机器同时向十几台机器拷贝快呢?如下图所示
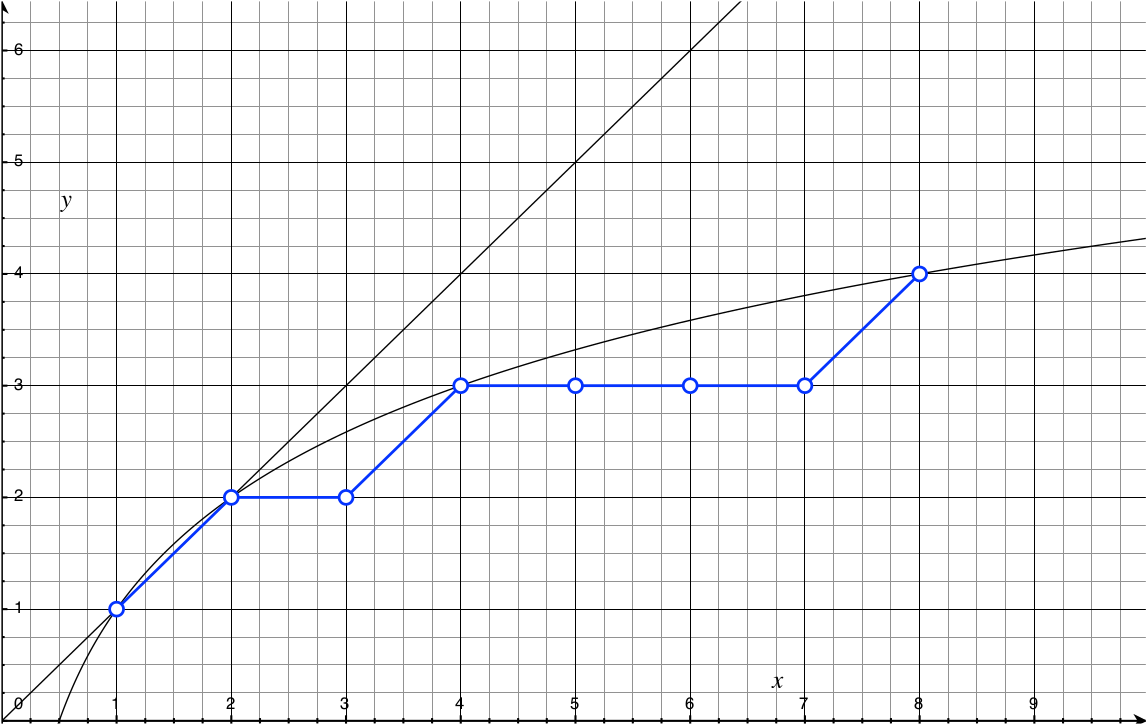
横轴是机器数量C,纵轴是size为S的文件从一台机器占满带宽B传输到另一台机器所需的时间T(T=S/B)。
- 用一台机器同时向其他机器分发的方法,花费时间和机器数量成正比,很好理解。
- 用B计划的话当只有有一台机器接收文件的时候需要一次对拷,花费时间T;当有两台机器的时候需要两次对拷,花费时间2T;当有三台机器的时候还是两次对拷,2T,如此这般,把线连接起来就是对数曲线,只要机器数大于两台就能保证这种方法更快。
用B计划的话就终于免不了IPC了,因为文件从母体A传输到机器B之后机器B得想办法告知机器A我收到文件了,可以作为新的母体向别的机器传播文件了,并且在原始母体机器上得有一个主控程序来控制整个分发流程的完成。
我设计的分发算法简单来说是这样的:
- 首先有三个集合set0,set1和set2,set0里包含已经持有完整文件可以向别的host分发的的host,set1包含没有文件待分发的host,set2包含正在发送或接收的host,初始状态是这样的:
- set0 = {A}
- set1 = {B, C, D, E, F, G}
- set2 = {}
- 从set0中pick出一个host作为发送方,从set1中pick出一个host作为接收方,讲这两个host放入set2,然后执行拷贝
- set0 = {}
- set1 = {C, D, E, F, G}
- set2 = {A, B}
- 重复上面这个过程直到:
- 当set1为空并且set2为空时分发结束
- 当set1为空但是set2不为空时说明正在执行最后一轮对拷,等待
- 当set0为空时说明没有足够的母体,等待
- 当某次传输完成后将发送方host和接收方host都从set2中取出来放进set0,然后重新触发上面的过程
代码我用node实现,在github上,叫bounce